05.04.26 By Sreenivas Vemulapalli

Part 2 of the Confidence Gap series, where defect prevention earns its place, and where AI actually helps
In Part 1 of the Confidence Gap series, we framed the confidence gap: organizations investing heavily in automation and AI, yet trusting releases less, not more. The root cause wasn’t effort or technology, it was misaligned expectations about what quality, automation, and AI each do.
The series promised to apply four questions to every capability in turn:
This post applies those questions to the earliest and highest-leverage layer: requirements and test case design. If the confidence gap starts anywhere, it starts here.
When organizations call us to ‘fix their automation,’ the conversation usually starts in the same place. Releases are slow and risky. The test suite takes hours and still misses defects. The team is spending more time maintaining tests than building features. Someone has just seen a vendor demo of an AI tool that promises to solve all of it.
We do not start by evaluating tools. We start by reading requirements.
In the majority of engagements, the root cause of brittle automation, expensive defects, and lost confidence is not in the test scripts or the tooling. It is upstream, in requirements that were ambiguous when development started, in acceptance criteria that were absent or wrong, in test cases that were designed to achieve coverage rather than to catch failures that matter.
You cannot automate quality into a system that was specified incorrectly. You can only discover its failures faster and more expensively.
This is the foundational insight behind shift-left quality. The test pyramid is not just a layering model. It is a cost model. And the cost of defects follows a ruthless multiplier as they move downstream.
IBM Systems Sciences Institute research, consistently replicated across decades of industry data, establishes a simple and inconvenient truth about software defects:
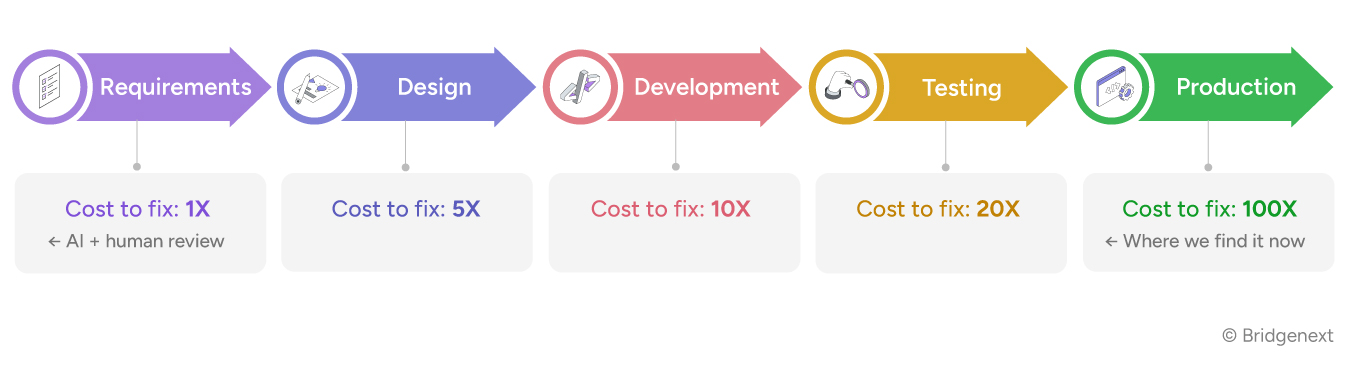
Every defect that escapes requirements review and reaches production costs 20 to 100 times more to fix than it would have at the point it was introduced. But the real cost isn’t just the engineering hours. It’s the release confidence a team forfeits while the pipeline is clogged with rework, the changes held back, the features delayed, the customer commitments that slip while a hotfix goes through change advisory. Organizations that invest heavily in end-to-end automation while neglecting requirements quality are not protecting themselves from this cost. They are deferring it, compounding it, and paying for it in delivery confidence.
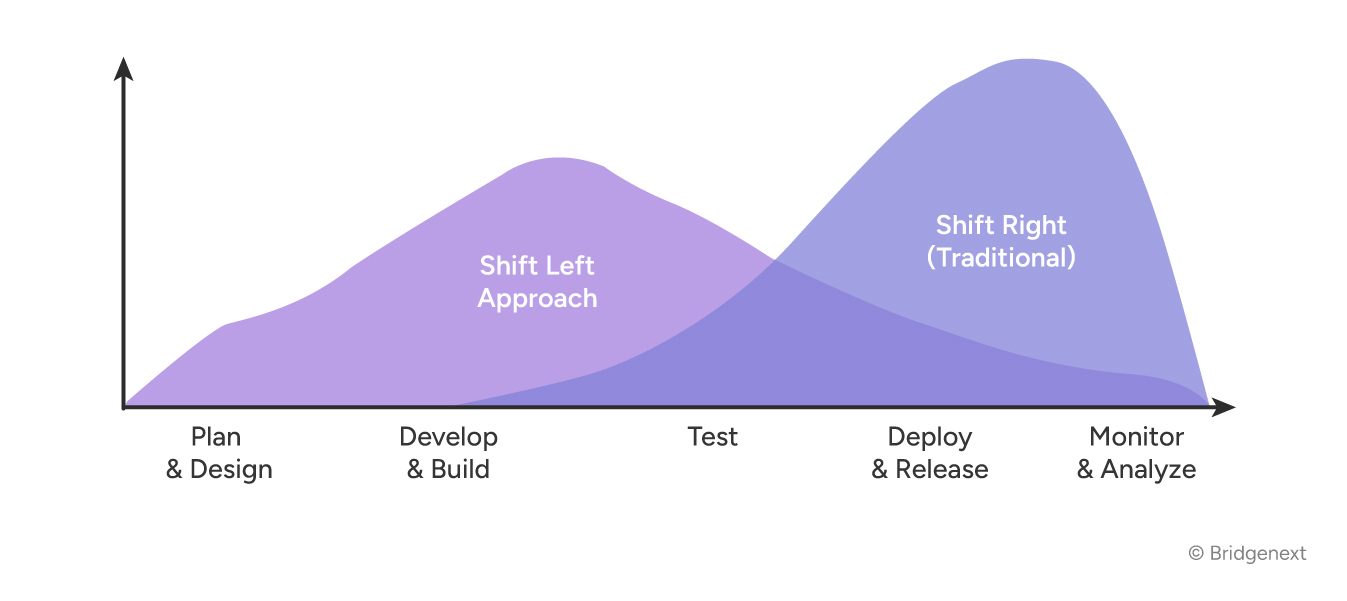
Before examining where AI fits in requirements and test case design, we need to establish the structural model that governs testing ROI. The test pyramid originally articulated by Mike Cohn and extended by the industry over two decades of CI/CD practice is not a preference. It is the outcome of learning, at significant cost, what works at scale.
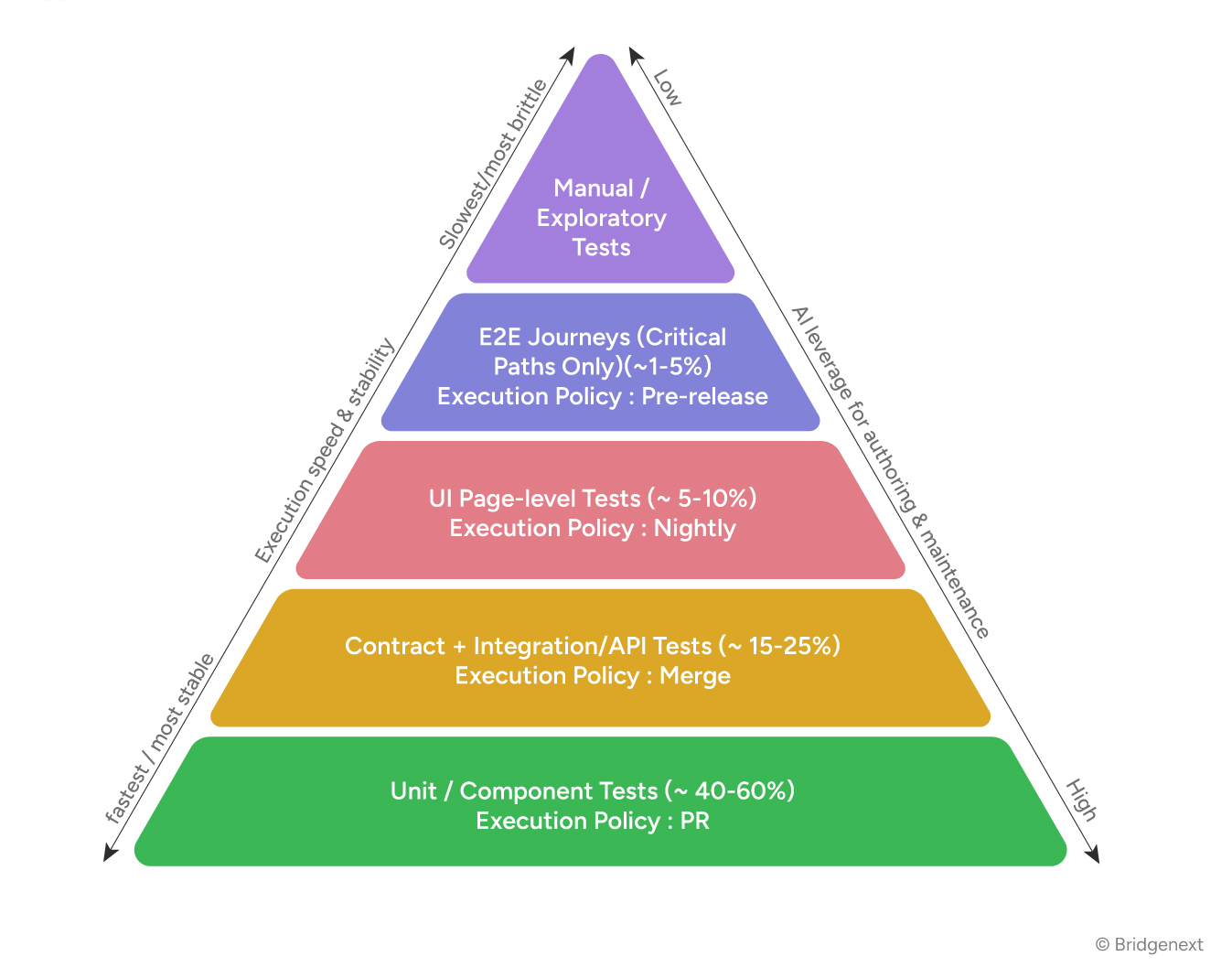
The pyramid encodes a straightforward principle: tests are most valuable when they are fast, stable, and close to the code. As you move up the pyramid, tests become slower, more expensive to maintain, and more sensitive to environmental change. The strategic imperative is to push as much validation as possible to the lowest stable layer.
This has a direct implication for requirements and test case design: the further upstream you can define and validate correct behavior, the cheaper it is to test it and the more of it you can test with confidence.
A business rule that is clearly specified in requirements can be tested comprehensively at the unit layer, fast, cheap, deterministic. The same rule, left ambiguous in requirements and discovered during E2E testing, requires a slow, expensive test that still may not cover all its conditions. And if it reaches production, it requires a production incident, a hotfix, and a retrospective.
Strong requirements do not just improve quality. They change where in the pyramid that quality is validated, and therefore what it costs.
With the pyramid as the structural frame, AI’s role becomes easier to position accurately. AI solutions have meaningful impact at every layer but the nature and limits of that impact vary significantly, and the highest-leverage intervention point is almost always the one teams underinvest in: upstream specification.
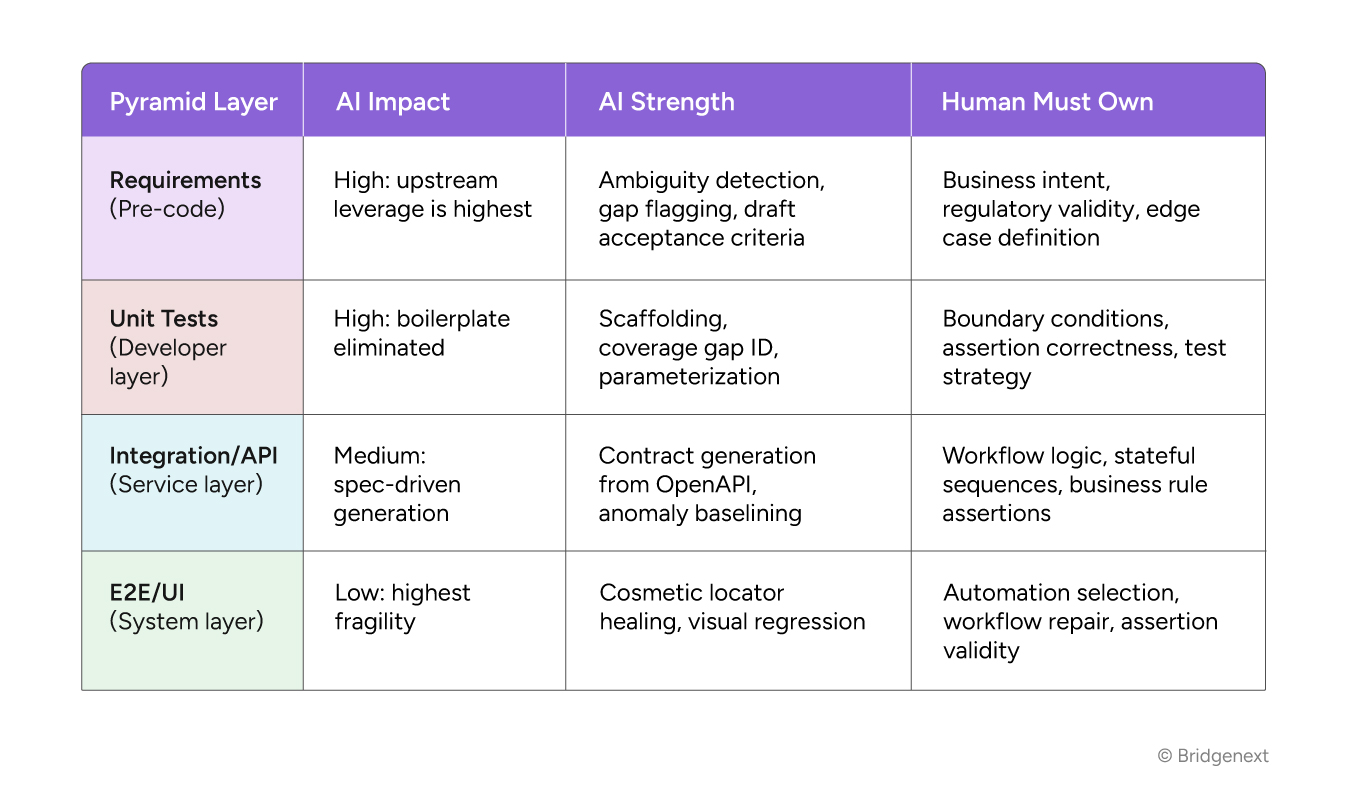
The pattern is consistent: AI performs best where the input is structured and the task is generative. It performs poorly where the input is ambiguous, the task requires business judgment, or the output needs to be verified against a standard that exists only in the minds of domain experts.
That description exactly characterizes requirements. Which is why getting requirements right, with AI as an accelerator not a replacement, is the single highest-leverage intervention available to any quality practice.
Most organizations treat requirements as a product management concern. In our experience, that is the first structural mistake. Requirements are a quality concern. They are where the definition of correct behavior is established and where the seeds of every downstream defect are either planted or prevented.
The most common failure pattern we encounter looks like this: a development team moves quickly, requirements are good enough to start coding, test cases are written after the code exists (validating what the code does, not what it should do), and the first time anyone formally validates correct business behavior is in UAT or production.
By that point, the cost structure of the pyramid has been completely inverted. The most expensive layer is doing the work that should have happened in the cheapest layer. AI tooling applied in this context does not fix the problem, it accelerates the cycle.
When requirements practice is healthy when there is a QA lead or Business Analyst with domain knowledge involved in specification, AI becomes a powerful force multiplier at three specific points:
The danger in requirements analysis is not that AI produces obviously wrong output. It is that AI produces plausible-sounding output that is wrong in ways only a domain expert can detect.
The sign that AI is being misused in requirements is when the review step disappears. When ‘AI reviewed the stories’ becomes a substitute for ‘a BA with domain knowledge reviewed the stories.’ Volume of acceptance criteria is not the same as quality of acceptance criteria. The AI can generate them. Only a human who understands the business can verify them.
Unit tests are the foundation of the pyramid, the fastest, cheapest, and most maintainable layer when done well. They are also the layer most frequently under-invested in, because writing meaningful unit tests requires the developer to reason explicitly about what the code is supposed to do. That reasoning is where defects are caught. Skipping it is where they are introduced.
AI-assisted unit test generation has become genuinely capable in a narrow but useful band: boilerplate elimination. Framework setup, import organization, mock initialization, basic happy-path and negative-case generation, these are tasks where AI saves real time without introducing meaningful risk, provided the developer reviews the output and completes the assertions.
The boundary appears clearly when business logic is involved. Consider a developer who has implemented a function that calculates a transaction fee based on account type, transaction amount, and time of day. AI generates tests that verify the function returns a number, handles null inputs, and produces different outputs for different inputs. What it does not generate, because it cannot know, are the specific fee schedule rules that the business requires, the rounding behavior at threshold boundaries, or the regulatory constraints that apply to certain account types.
A team uses Generative AI solutions to build unit tests for a new pricing calculation module. The tool produces 140 test cases with 94% line coverage. Code review passes. Three weeks later, a production incident surfaces: the module applies the wrong rounding logic for transactions in currencies with no decimal precision. None of the 140 generated tests covered that case, because the business rule was not in the code the AI analyzed. It was in a compliance document that the developer had read but not translated into the implementation.
Coverage percentage: 94%. Business rules validated: incomplete. Production defect: shipped. None of this is a failure of the developer’s effort, it’s a failure of the surrounding practice to make the business rule visible to the code.
The shift AI creates at the unit layer is not from human testing to AI testing. It is from developer time spent on boilerplate to developer time spent on what matters: designing the boundary conditions, writing the assertions that validate business rules, and ensuring that the test strategy at the unit layer actually covers the behaviors that will cause production failures.
Test case design is the discipline that determines how validation is distributed across the pyramid. Done well, it concentrates coverage where it is cheapest and most reliable, unit and API layers, and uses E2E testing selectively for workflows that cannot be validated any other way. Done poorly, it produces a test suite weighted toward slow, fragile E2E tests that cover what is easy to see, not what is important to validate.
AI’s role in test case design is significant, and its failure modes are predictable.
Teams that adopt AI test case generation typically see their test case inventory grow 3x to 5x within weeks. This is reported as progress. In our assessments, it is usually a warning sign.
A test repository with 5,000 AI-generated test cases, imprecise assertions, and no domain-expert curation may provide less meaningful coverage than 1,000 carefully designed human-authored cases. AI generates completeness across obvious scenarios. It does not generate depth across scenarios that matter.
The diagnostic question is not ‘how many test cases do we have?’ It is ‘which production failures would our test suite catch, and which would it miss?’ AI-generated suites consistently struggle to answer this question because the cases are generated from specification structure, not from production failure history.
Within a disciplined framework, AI contribution to test case design is real:
The failure modes in AI-generated test cases are architectural, not cosmetic:
When we engage with an organization whose quality practice is holding back delivery confidence, the intervention sequence is consistent. It’s not about replacing tools. It’s about restoring the conditions under which any tool, AI or otherwise, can produce reliable output, and under which the release pipeline can carry the changes the business actually needs to make.
| Phase | Our Intervention | What the Business Gets |
|---|---|---|
| Requirements Gate | QA reviews every story before sprint entry using AI to flag ambiguity, missing acceptance criteria, and untestable scope | Defects caught at 1× cost instead of reaching production at 100×, and release capacity freed up for the features the business actually needs to ship |
| Testability Standard | No story enters development without explicit success conditions, failure modes, and at least one boundary condition defined | Unit tests can be written against specification, not implementation, eliminating the mirroring problem and shortening the path from idea to production |
| AI-Assisted Draft Review | AI generates acceptance criteria and initial test case scaffolding; domain expert reviews for business correctness | BA time shifts from blank-page authoring to expert validation, higher-value work, faster throughput, and more capacity to focus on what matters |
| Pyramid Alignment | Test cases are explicitly assigned to pyramid layers during design; E2E coverage is justified, not assumed | Maintenance cost is front-loaded into design decisions rather than discovered at scale, which keeps the release pipeline predictable |
| Mutation Gate for Unit Tests | AI-generated unit test suites pass mutation testing before entering CI pipeline | Coverage percentage reflects behavioural validation, not execution completeness, and leadership can trust the quality signal before committing to a release |
| Institutional Edge Case Library | Post-incident reviews feed a curated library of edge cases that AI cannot generate; library is maintained as a quality asset | Production failure history becomes a testing advantage rather than a recurring liability, and confidence grows to release more ambitious changes |
The sequence matters. Each step creates the conditions for the next. Requirements that are testable enable unit tests that are meaningful. Unit tests that validate business rules, not just code paths, enable a test pyramid that distributes coverage efficiently. A pyramid that’s efficiently shaped enables automation investment to return maintenance savings, and, more importantly, release confidence the business can actually rely on.
Requirements, unit tests, and test cases all involve writing. That surface similarity is what makes AI assistance look so directly applicable, and what makes the failure mode so common. The value of each artifact is not in its text. It is in its correctness relative to a system and a business context that exists outside the document.
AI can produce volume. It cannot validate intent. In upstream quality work, that distinction determines whether you are building confidence or manufacturing it.
The teams we’ve worked with that are extracting genuine value from AI in upstream quality share three characteristics: they use AI to eliminate low-value structural work; they hold human ownership of correctness judgment as a non-negotiable gate; and they measure the quality practice by what it prevents, not by how much it generates.
Where we see teams struggle, the pattern is different: AI tooling gets adopted to accelerate a process that was already producing incorrect output. The output becomes incorrect faster. The test suite grows larger. Confidence drops. The production incidents continue, and the confidence gap the series opened with only widens.
Getting requirements right isn’t a prerequisite to using AI in quality programs. It’s the prerequisite to getting value from anything else in this series, and to closing the confidence gap rather than automating around it.
| AI: Reliable Value | Human: Must Own |
|---|---|
| Flag ambiguous language and structural gaps in requirements | Validate business intent and regulatory correctness |
| Draft acceptance criteria from well-formed user stories | Define what “correct” means for the business, not as language, but as judgment |
| Generate unit test scaffolding and boilerplate | Design boundary conditions from domain knowledge and spec |
| Identify coverage gaps in existing test suites | Write assertions that validate business rules, not code execution |
| Produce structural test cases from specified stories | Encode institutional edge cases from production failure history |
| Expand scenario matrices combinatorially | Determine assertion completeness and pyramid layer allocation |
| Flag orphaned requirements with no test coverage | Own the decision that a requirement is ready to drive development |
Part 3 moves from specification to the developer’s workbench: unit and component testing. This is the layer where AI tooling is most actively deployed, where the productivity gains are most visible, and where the failure mode of over-trusting generated output is most consequential. We examine what AI changes about how developers test, where the boilerplate-versus-business-logic boundary sits, and the specific practices that make AI-generated unit tests worth keeping.
Talk to our practitioners about where the requirements and test-design layers of your delivery model stand today, and the highest-leverage moves to strengthen them.
References
IBM Systems Sciences Institute — Relative Cost of Fixing Defects by Phase
NIST — The Economic Impacts of Inadequate Infrastructure for Software Testing
Mike Cohn — Succeeding with Agile: Software Development Using Scrum
ISTQB — Foundation Level Syllabus: Test Design Techniques
Agile Alliance — Acceptance Test-Driven Development (ATDD) Reference
Capers Jones — Applied Software Measurement, 3rd ed.









