10.18.21 By Shavya Agarwal

The reign of diverse applications is here! Web, desktop, and mobile applications are now being leveraged by business functions across the organization – from sales, marketing & customer service – to finance, human resources and more! These applications have a single goal – to provide a stunning user experience. To achieve this, organizations –
While they may provide a seamless user experience, most organizations fail to derive and harness critical insights from their applications once launched. These insights play a key role in both enhancing future application performance and fulfilling strategic business goals.
A 2019 Gartner report suggests, “Through 2022, only 20% of analytic insights will deliver business outcomes”. This clearly states the maturity and success of data analytics projects. What is the cause of this failure? People and processes. Often, organizations lack the skills or processes to effectively harness and leverage the vast amount of data their applications create for meaningful insights.
Organizations that leverage data effectively can quickly mitigate their process, people, and tools-related challenges. Here’s where DataDevOps, also called DataOps can help.
DataOps is a common technical platform wherein you can plug-in data and tools from diverse business processes for centralized processing and cross-functional insights. The orchestration of this entire process including ingestion and enrichment is executed within a data factory. This provides the basis for data discovery, analytics, and insights as required by respective business stakeholders.
In this blog, we will guide you through the steps for DataOps implementation and provide a case study that showcases how you can utilize Azure/AWS to achieve your DevOps objectives.
DataOps enables you to analyze and derive insights from data that is generated by every business process and activity in an organization, something that isolated data stores are unable to do.
DataOps implementation answers these technical questions across business processes
A successful DataOps implementation can provide numerous benefits
Data Research refers to studying business processes, process-generated data, and identifying KPIs and insights that these data sets could provide together. If/when you’re posed with challenges related to data research, try getting answers to the following questions-
The first and most important task is to bring in data from disparate systems, into one common datastore and then standardize the data format across as many systems as possible.
Some of the common questions you might need to answer during this stage are as follows
The next step is to use the ingested data to generate insights. This requires creation of script(s) that transform the ingested usable insights/KPIs and create reports to present these insights to the audience. Some of the best practices for this step are –
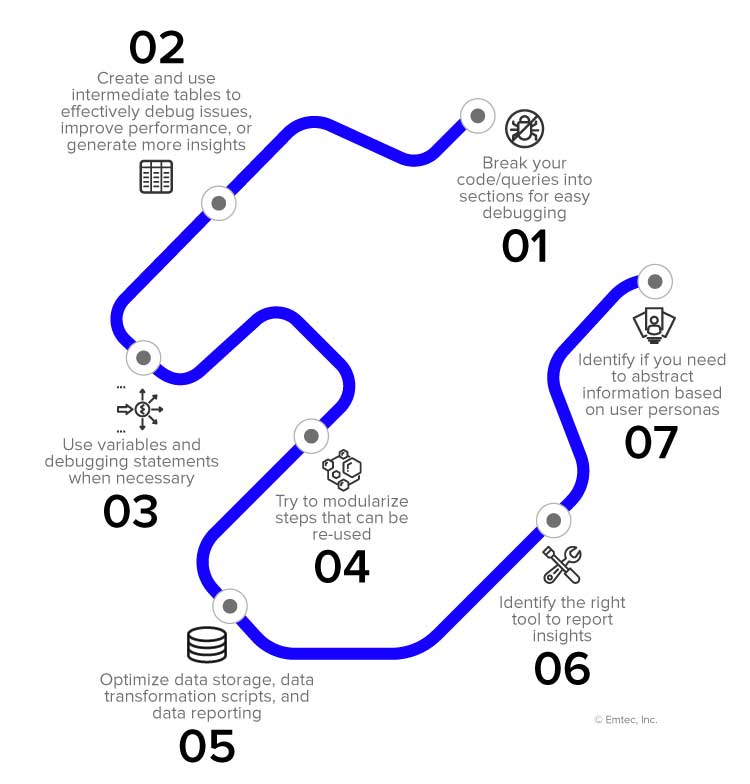
This step comprises of automating data ingestion and transforming it into insights. This automation is generally called creating “data pipelines”. These “data pipelines” can be scheduled to run automatically or can be configured to execute based on specific triggers (when a previous pipeline finishes, when data is available, or when it is manually executed). Based on the system in use and the type of data, a vast variety of tools and options are available to achieve this. Further, each tool can have multiple ways of creating these pipelines. Here are the steps to create data pipelines-
After achieving automation to derive data insights, it is followed by other maintenance processes (such as managing code and infrastructure) free of manual intervention. This also helps reduce human overhead of deploying new versions of the application and pipelines. Some of the benefits gained from this are-
Git is a very popular tool to store and version code. Several different flavors of git are available, like Gitlab, etc. This is widely supported in most IDEs and enable multiple people to work together without affecting each other’s work or hampering releases. It also provides an effective management tool for project owners to track and review their team’s work.
Most tools/services (AWS, Azure, etc.) allow the automation of infrastructure provisioning and configuration. This not only helps in the initial setup but also during infrastructure updates and disaster recovery processes. Some of the steps that need to be followed are –
Scripts and tools (like Jenkins) can be used to deploy an application to its provisioned infrastructure.
Writing automated test cases is almost a mandate now. These tests can be executed right after the code is deployed and can be used for a variety of purposes such as-
A variety of tools are now available that help create an end-to-end pipeline for infrastructure provisioning, deploying code/reports/configurations, and running automated test cases. These deployment pipelines can even be scheduled to run automatically. Examples include Gitlab CICD and Jenkins.
There are a few other automation-related operations which can be incorporated in the later stages of your DataOps implementation-
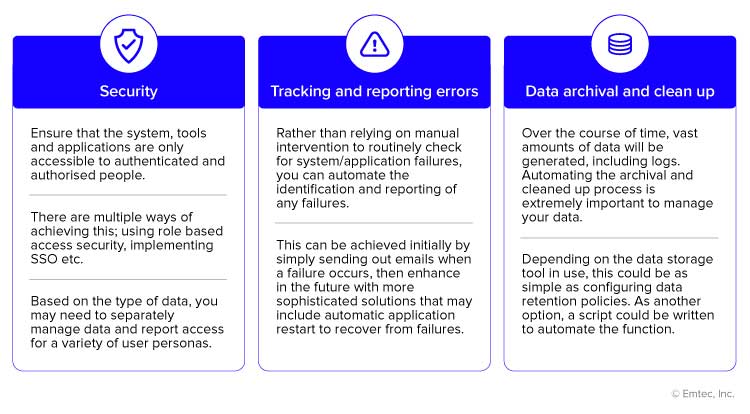
A successful DataOps implementation can provide numerous benefits
Do you want to successfully implement DataOps and enhance your data analytics efficiency?
Contact our data experts today!