06.03.26 By Dan Federoff

Your first AI POC is live and the outputs are wrong. The model looks fine. The data isn’t.
This is where most AI projects fail, not in the algorithm, not in the infrastructure, and not because the use case was wrong. They fail due to the data feeding the model. We’ve seen it happen across industries, across team sizes, across technology stacks. The pattern is consistent enough that it’s worth sharing why it happens and what a practical fix looks like.
Your AI model is only as smart as the data you feed it. Right now, many enterprises are feeding it an incomplete mess, because data debt accumulates quietly until something forces it into view. AI has a way of doing exactly that.
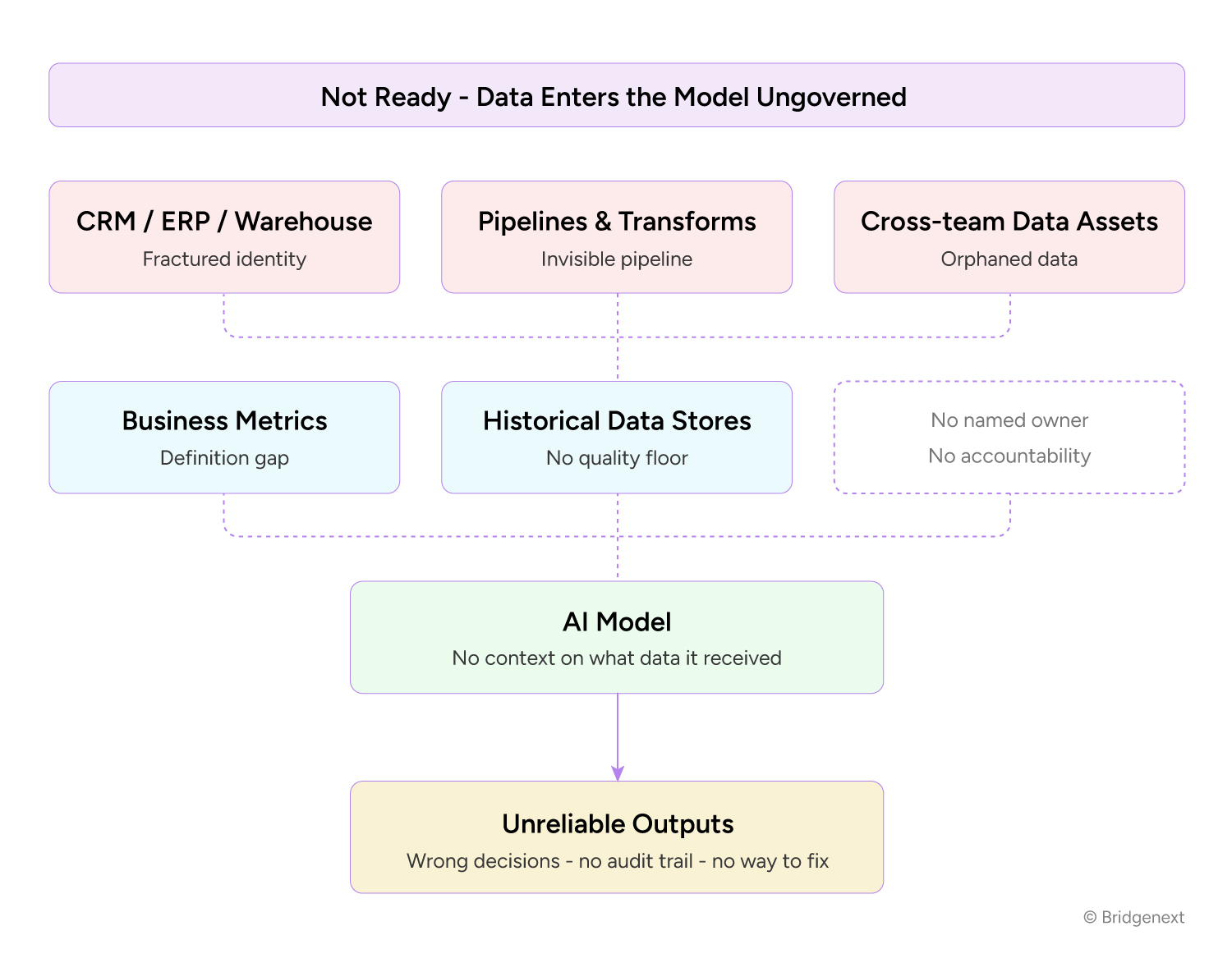
Data from five broken sources converges on the model through dotted, uncertain lines. The sixth source box (bottom right) is deliberately empty with a faint border, representing the orphaned data pattern, produced by no one, owned by no one. Before getting into the framework, it helps to name the specific challenges we see most often. These aren’t hypothetical, they’re scenarios we see repeatedly in the first weeks of a data readiness engagement.
None of these challenges are unusual. Many data environments have some – if not all five to some degree. The difference is whether you’ve made them visible before your model goes live, or after.
Addressing these challenges doesn’t require a platform overhaul or a multi-year transformation program. It requires getting five foundational domains in order, what we think of as the five rooms in a data house. These aren’t aspirational. They’re the minimum viable structure for AI outputs you can trust.
These five domains are the prerequisite for building an AI foundation you can defend.
The instinct when faced with a governance gap is to scope the solution to match the scale of the problem. That instinct usually kills the effort in planning. What’s worked better, in environments we’ve seen navigate this successfully, is to scope governance to your first AI use case, not to your entire data estate.
Here’s a 90-day sequence that’s proved workable.
Days 1 – 30: Assessment. Identify which data domains your first AI use case actually touches. Run a readiness check across those domains, quality, ownership, lineage, access. Document current state, not ideal state. The output here is a gap map, not a strategy deck. You’re building a picture of what exists, not a plan for what should exist in three years.
Days 31 – 60: Stewardship. Assign a named owner to each domain in scope. Establish a documented quality baseline with measurable thresholds, not targets, but a current-state benchmark you can track against. The output is accountability on paper and in practice: a person’s name next to each data asset your model will consume.
Days 61 – 90: Lineage and readiness gate. Build lineage for those domains. Define a go/no-go readiness gate, a set of conditions that have to be true before the model goes live. If you can’t explain the data to an auditor, you’re not ready to explain a model output to a stakeholder. The output is a defensible AI launch, not a hope that the model behaves.
This is not a 12-month project. It’s not a platform purchase. Eight weeks of scoped, focused work delivers the data foundation a first use case needs, and a repeatable pattern for every use case that follows.
Most organizations treat data governance as compliance overhead, the thing you do because legal said you had to, or because regulations require it. The organizations that are getting consistent ROI from AI tend to treat it as an investment. The same category of thinking that justifies spending on compute, storage, and tooling.
The value chain is direct:
Governed Data → Trusted Model Outputs → Faster Time-to-Decision → Measurable Business Value
That chain doesn’t work in reverse. You can’t trust the outputs of a model trained on ungoverned data, and you can’t accelerate decisions on outputs you can’t trust.
The cost of ungoverned data isn’t visible until AI makes it loud. A governance gap that took years to accumulate will show up in a failed AI deployment very quickly. At that point, the cost isn’t just a delayed project. It’s trust in the AI program itself.
One reframe that’s helped in our conversations with both technical and business teams: AI doesn’t create a data problem. It reveals the one you already had. Governance is the work of making that problem visible and traceable before it becomes expensive, before a model has amplified it across every prediction, every recommendation, every decision it touches.
You wouldn’t move a data center into a building without fire code compliance. The risk isn’t theoretical; it’s the condition under which something bad becomes inevitable. Data governance is the same kind of prerequisite, not the interesting part of the work, but the part that determines whether the interesting part holds up.
Does this resonate with what you’re seeing in your environment? A useful next step is usually a scoped assessment, not a broad audit, not a multi-year roadmap, but a structured look at the data your first AI use case depends on.
Bridgenext’s Data Readiness Assessment scopes to a single use case and delivers a prioritized gap map and a 90-day action plan. It’s designed to answer one question: are you ready to deploy, and if not, what specifically needs to change first.
If that’s a conversation worth having, [we’re easy to reach].
Most AI projects fail because of poor data quality, inconsistent definitions, weak governance, and missing lineage. When AI models train on unreliable data, those issues scale into inaccurate and non-auditable outputs.
A data readiness assessment checks whether enterprise data is suitable for AI deployment. It evaluates quality, ownership, lineage, and access controls for the specific use case and identifies critical gaps to address.
For a focused AI use case, foundational data governance can typically be established in about 90 days, covering readiness assessment, ownership, quality baselines, and lineage documentation.
Data lineage tracks where data comes from, how it changes, and where it is used. In AI systems, it enables traceability, auditability, and faster root-cause analysis when outputs are incorrect.
Data governance improves AI reliability, speeds decision-making, and reduces operational risk. Organizations that invest in governance early typically achieve faster and more scalable AI outcomes.






