08.24.23 By Bridgenext Think Tank

ML models need limitless and diverse datasets for training. How do you get original datasets without breaking any privacy regulations? Read on to know why AI-generated synthetic data is gaining popularity!
Software engineers and data scientists frequently require access to massive volumes of real data to develop, experiment with, and innovate. Unfortunately, gathering such data poses security and privacy risks, impacting people, businesses, and society. Regulations like GDPR increase obstacles by limiting data collection, usage, and storage while providing legal protection for user data. When developing and innovating through Artificial Intelligence and Machine Learning, access to data is a significant barrier.
35% of the time spent on a typical project is spent on the “data gathering” stage, according to 20,000 data scientists. – Kaggle Study
Running a neutral machine-learning model that generates insightful insights for various circumstances requires many data sets to accurately capture the depth, granularity, and variety of real-world situations. Finding data is always tricky, and different model types require additional data. While more complicated algorithms require tens of thousands (perhaps millions) of data points, linear techniques only require a few hundred samples per class. In general, you need ten times as many examples as degrees of freedom in your model.
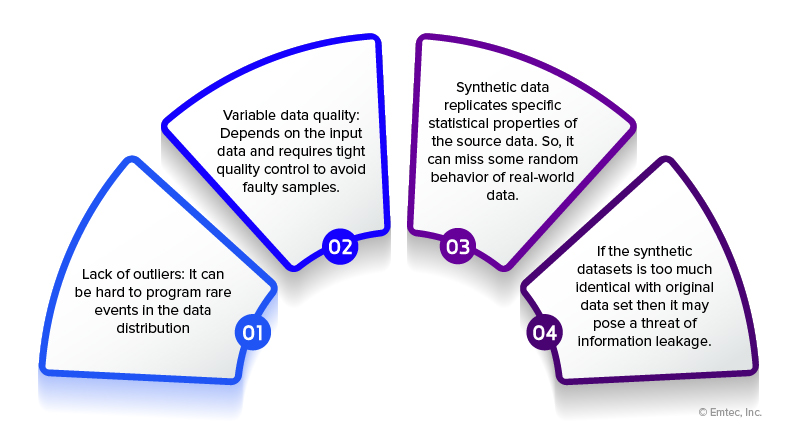
A model is more likely to overfit if insufficient data prevents it from effectively analyzing brand-new data. The model may be skewed and fail to capture the realities of the environment where it will be used if certain data types for populations are absent. A proportionally precise sample size of each population member, including different instances and combinations, is required for training data. This is considerably worse in anomaly identification issues because the uncommon pattern necessary may need to be present in sufficient quantities. Businesses may also experience the problem of incomplete data, where data sets need specific attribute values. So, what options do you have to eliminate this barrier?
In contrast to “real” data gathered through real-world surveys or events, synthetic data, as its name implies, is essentially “fake” data that is artificially generated. Real data is used to create this synthetic data. An excellent synthetic dataset can capture the underlying structure and show identical statistical distributions as the original data, making them indistinguishable. When real historical data sets are insufficient in quality, volume, or variety, artificially created data might be used to train AI/ML models in their place. When existing data doesn’t satisfy business requirements or could compromise privacy if utilized to develop ML models, test software, or the like, synthetic data can be a crucial tool for enterprise AI initiatives.
By 2024, 60% of the data required to develop AI and analytics solutions will be synthetically generated. – Gartner
Three types of synthetic data exist – completely synthetic, hybrid, and partial. Depending on how complex the use case is, there are multiple approaches to creating and perfecting synthetic datasets, such as:
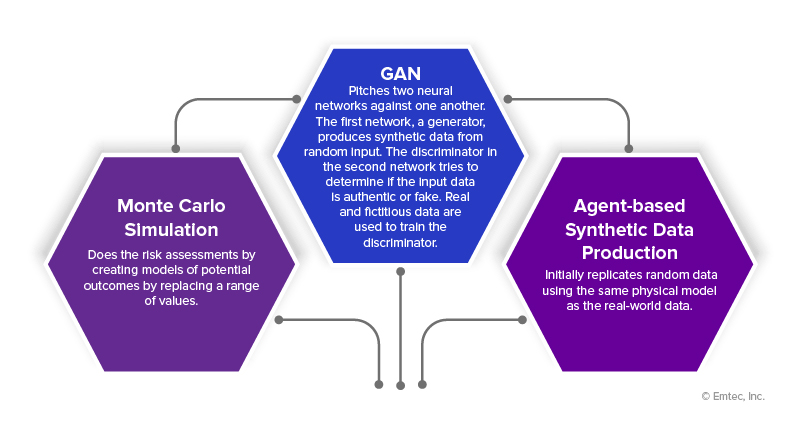
Artificial intelligence has become more commonplace because of new generative AI models like DALL-E 2, Stability AI, and Midjourney. Synthetic data, a byproduct of advanced generative AI, solves privacy and bias hazards. These algorithms can produce infinite amounts of generative AI synthetic data with the same statistical properties using learned data structures and correlations, preserving insights with fresh, synthetic data points. The procedure is, by design, private and compliant, and it can reveal information with a high privacy value and remove prejudice and imbalances.
According to a Gartner report, by 2030, synthetic data will completely overtake real data in the AI model development process. – Gartner
Think of it as translating the text into a separate artificial language. Modern text-to-image models use a decoder model to turn the compressed representation of the text into a picture. The “diffusion” process is the secret ingredient in the most recent models. With diffusion, a model learns to consider the “translated” text and iteratively build realistic images from random noise. Using a diffusion-based model for the decoder component can significantly enhance the outcomes. Concepts, characteristics, and styles can be combined in text-to-image models using diffusion-based decoders to produce images from descriptions in natural language. Using generative AI, diffusion models can also generate animations from static images based on synthetic data. See this example of a living and talking portrait of the Mona Lisa:

(Img ref – https://www.smithsonianmag.com/smart-news/mona-lisa-comes-life-computer-generated-living-portrait-180972296/)
Today’s applications are primarily concerned with creating art and media. However, these models will soon be integrated into synthetic data production pipelines to enable the scalable generation of unique textures for 3D objects, assist in composing complicated scenes, improve displayed sceneries, and even directly generate 3D assets.
5.1 For Responsible AI
In the data-driven world, automated bias is escalating. Gartner estimates that 85% of algorithms are now biased and incorrect. Currently, many businesses exclude data about gender and race. However, this won’t eliminate the bias, making it more challenging to spot biased AI decisions. By modeling data with suitable balance, density, distribution, and other parameters, synthetic data generation reduces dataset bias and, in turn, helps ML projects solve their data quality issue.
5.2 For Explainable AI
Many rapidly advancing sectors use XAI to verify their ML models. Artificial data makes it easier to evaluate model decisions and makes algorithms more visible. By examining a system’s choices across numerous situations and testing its sensitivity to changes, synthetic data can be used to understand its behavior better.
The development of synthetic data will ultimately empower a whole new generation of AI upstart startups and unleash AI innovation by reducing data barriers to creating AI-first solutions. By democratizing access to data, it will accelerate the adoption of AI throughout society. Though synthetic data is not new, its potential for real-world benefit is at a critical crossroads. With significant economic ramifications, it could upend artificial intelligence’s entire value chain and technological foundation.
For ML model training, synthetic data should be comparable to production data sets. Still, it must not be too similar because it can exchange much information. Contact Bridgenext (former Emtec Digital) if you want a trusted partner to balance and produce synthetic data and develop effective AI-driven applications. We offer NLP, AI-driven analytics, and maintenance as our AI/ML services suite.
Get in touch with us today!
References
www.kaggle.com/code/sudalairajkumar/an-interactive-deep-dive-into-survey-results/notebook
emtemp.gcom.cloud/ngw/globalassets/en/data-analytics/documents/generative-ai-for-synthetic-data-peer-community.pdf
www.forbes.com/sites/robtoews/2022/06/12/synthetic-data-is-about-to-transform-artificial-intelligence/?sh=2c08f0a27523